
2025年度国际声学语音与信号处理会议——ICASSP在印度海得拉巴举办,作为语音领域的国际会议,其凭借权威、广泛的学界以及工业界影响力,备受各方关注。今年许多学者因故无法前往印度参加会议。考虑到广大学者的现场交流需求,IEEE信号处理学会特别安排ICASSP 2025在5月23日-25日于苏州举办卫星会议。思必驰-上海交大联合实验室团队将参与本次现场交流。
在本次ICASSP 2025会议上,思必驰-上海交大联合实验室共发表了12篇论文,涵盖了音频信息处理、语音唤醒识别、语音合成、多模态生成等研究方向,实现了若干针对噪声环境、低资源、多语种、多模态等场景的技术突破,为思必驰的全链路语音语言核心技术实力以及业务创新能力带来多重增益。下面介绍本次发表的部分典型研究成果:
音频信息处理
Neural Directed Speech Enhancement with Dual Microphone Array in High Noise Scenario
针对多说话人场景实现了目标语音的灵活增强,仅使用双麦克风阵列就显著提高了语音质量和下游任务的性能,尤其是在极低信噪比条件下表现出色。
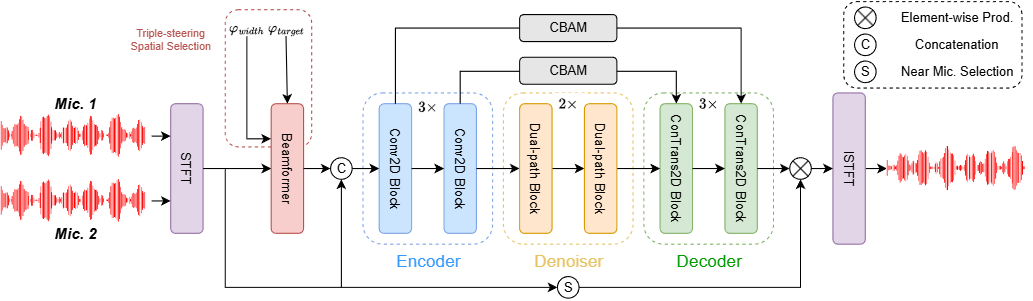
工作简介:在多说话人场景中,利用空间特征对增强目标语音极为关键,但麦克风阵列有限时,构建紧凑的多通道语音增强系统颇具挑战,极低信噪比下更是难上加难。为此,我们创新提出三导向空间选择方法,打造灵活框架,用三个导向向量指导增强、界定范围。具体引入因果导向的U型网络(CDUNet)模型,以原始多通道语音与期望增强宽度为输入,据此依目标方向动态调导向向量,结合目标和干扰信号角分离微调增强区域。该模型仅凭双麦克风阵列,就在语音质量与下游任务表现上十分出色,还具备实时操作、参数少的特性。
语音唤醒识别
NTC-KWS: Noise-aware CTC for Robust Keyword Spotting
针对噪声环境下的关键词识别提出“NTC-KWS”,强化了在车载、家电等噪音场景下的唤醒和识别精准度,也为资源受限设备带来高鲁棒性的端到端方案。
工作简介:当前基于CTC的小型化关键词识别系统在低资源计算平台上部署时,因模型尺寸和计算能力限制,面临噪声过拟合问题,导致高误报率,尤其在复杂声学环境下性能显著下降。因此,我们在CTC-KWS的框架下提出一种噪声感知关键词识别系统(NTC-KWS),创新性地引入两类额外的通配符弧对噪声进行建模:自环弧处理噪声导致的插入错误,旁路弧应对噪声过大造成的掩蔽和干扰,旨在提高模型在噪声环境中的鲁棒性。实验表明,NTC-KWS在各种声学条件下优于现有端到端系统和CTC-KWS基线,低SNR条件下优势尤为显著。该工作为资源受限设备提供了轻量化且高鲁棒的关键词识别方案,其噪声建模机制可扩展至其他端到端语音敏感任务。
语音合成
VALL-T: Decoder-Only Generative Transducer for Robust and Decoding-Controllable Text-to-Speech
针对鲁棒、可控语音合成提出“VALL-T”(生成式Transducer模型),进一步提升了思必驰在多语种、多场景高保真TTS方面的性能稳定性。
工作简介:当前基于decoder-only Transformer架构的TTS模型缺乏单调对齐约束,导致发音错误、跳词和难以停止等幻觉问题,严重制约其实际应用可靠性。
因此,我们提出了VALL-T,即生成式Transducer模型,它为输入音素序列引入了移位的相对位置编码,明确地限制了单调的生成过程,同时保持了decoder-only Transformer的架构。实验表明,我们的模型对幻觉表现出更好的鲁棒性,词错误率相对降低了28.3%。此外,还可以通过对齐的可控性实现跨语言适配和长语音稳定合成。
多模态生成
Smooth-Foley: Creating Continuous Sound for Video-to-Audio Generation Under Semantic Guidance
“Smooth-Foley” 视频到音频生成模型,扩展了智能汽车、智能家居、虚拟数字人等垂域解决方案上的产品形态,为思必驰进一步拓展视听融合交互提供技术储备。
工作简介:视频到音频(V2A)生成任务需同步满足高精度时间对齐与强语义一致性,但现有方法因低分辨率的语义条件与时间条件不够精确的限制,难以处理动态物体视频中的复杂声景生成。因此,我们提出了Smooth-Foley,一种视频到音频的生成模型,不仅在生成过程提供文本标签的语义引导,以增强音频的语义和时间对齐;还通过训练帧适配器和时间适配器以利用预训练的文本到音频生成模型。实验表明,Smooth-Foley在连续声音场景和一般场景中均优于现有模型。生成的音频具有更高的质量并更好遵循物理规律。
多模态生成
SLAM-AAC: Enhancing Audio Captioning with Paraphrasing Augmentation and CLAP-Refine through LLMs
“SLAM-AAC”通过高性能模型、创新的数据增强和解码策略,显著提升了音频字幕生成的性能。该项工作是开源项目“SLAM-LLM”的一部分,积极推动多模态大模型技术的创新与发展,促进全球研究者的技术交流与合作。
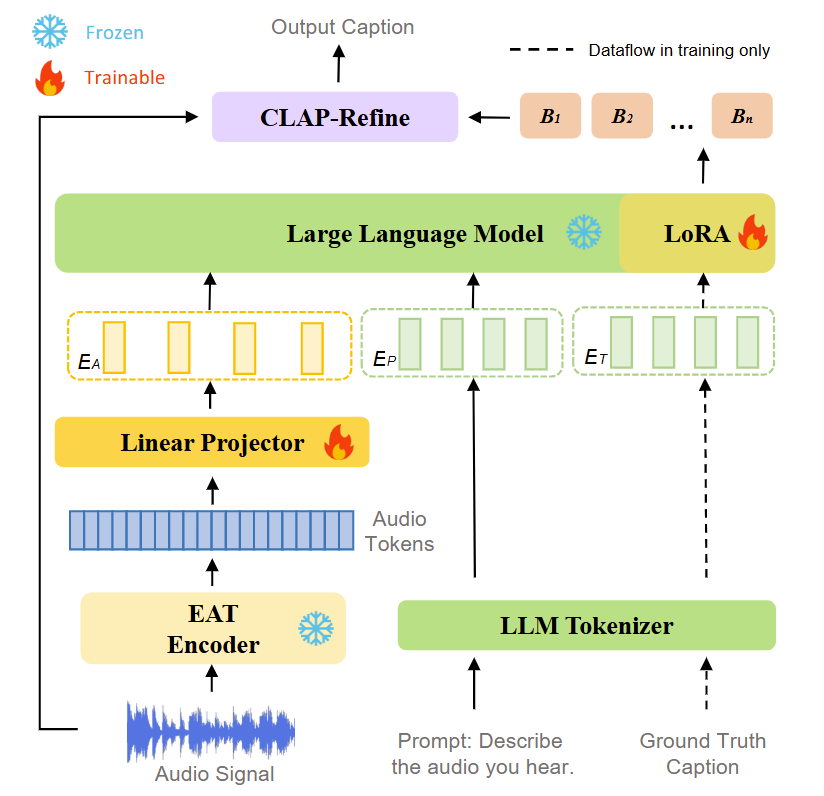
工作简介:尽管目前音频预训练模型与大语言模型(LLMs)的发展为自动音频描述(AAC)提供了更强的音频理解和文本生成能力,但如何高效对齐多模态特征并利用有限数据仍是关键问题。因此,我们提出SLAM-AAC,通过两阶段创新策略优化AAC:首先,借鉴机器翻译中的回译方法,扩展Clotho数据集的文本多样性,缓解数据稀缺的问题;其次在推理阶段引入即插即用的CLAP-Refine方法,从多个束搜索生成的文本描述中选择与音频最匹配的描述。实验表明,SLAM-AAC在Clotho V2和AudioCaps数据集上显著超越主流模型,该工作为小规模音频-文本数据下的AAC提供了可扩展解决方案,使其有可能用于其他多模态生成任务。
ICASSP (International Conference on Acoustics, Speech and Signal Processing) 即国际声学、语音与信号处理会议,是IEEE(电气与电子工程师协会)主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。2025年度ICASSP会议主题是 “Celebrating Signal Processing”,旨在庆祝信号处理领域的卓越成就与创新突破。
长期以来,思必驰深度融入国内外学术前沿阵地,在 ICASSP、INTERSPEECH、ACL、EMNLP、AAAI 等顶尖学术大会上屡创佳绩,持续输出高质量科研成果。思必驰-上海交大联合实验室通过一系列高水准论文,展现出在人工智能语音语言关键技术领域的深度探索与重大突破,为行业发展注入强劲动力。思必驰坚定科研与产业应用密切结合,也将继续探索科技成果的应用转化。
作为专业的对话式人工智能平台型企业,思必驰具有源头技术创新和应用创新的能力,自2022年7月获国家科技部批准建设“语言计算国家新一代人工智能开放创新平台”以来,接连于2023-2024年获批组建苏州市、江苏省、长三角三级创新联合体,并于2025年携手上海交通大学、苏州大学,牵头组建“江苏省语言计算及应用重点实验室”,成为国家人工智能战略科技力量的重要组成部分。
思必驰承担了包括国家重点研发计划、国家发改委“互联网+”重大工程和人工智能创新发展工程、国家工信部人工智能与实体经济深度融合项目、长三角科技创新共同体联合攻关计划项目等十余项国家级、省部级项目,展现出卓越的科研实力与项目落地能力。
思必驰深耕语音语言领域,凭借自主研发的核心技术多次在国际研究机构评测中夺得冠军;曾三度斩获国内人工智能最高奖“吴文俊奖”,荣获中国专利优秀奖,以及信通院车载智能语音交互系统最高级别认证等重要荣誉。技术创新能力备受全球瞩目,被高盛全球人工智能报告列为关键参与者,也被Gartner评为东亚五大明星AI公司之一。
截至2024年年底,思必驰拥有近100项全球独创技术,已授权知识产权1597件,其中已授权发明专利633项,参与了71项国家/行业/团体标准,获得23项国家级的产品认证。近期,大模型人机对话技术创新与产业赋能发展提速,思必驰坚持自主的大模型技术路线,即“构建可靠性优先的1+N分布式智能体系统:1 个中枢大模型+ N 个垂域模型及全链路交互组件组成全功能系统”,以任务型交互为核心,结合智能硬件感知优势,构建垂域大模型和中枢大模型系统,服务企业客户。










